Hidden Technical Debt in Machine Learning Systems
03 Feb 2023Technical Debt is a metaphor that stands for the extra cost that arises in the long term that a team faces and results by selecting easy and quick delivery options instead of optimal development or missing crucial points in action. The term was first mentioned by Ward Cunningham in 1992. Cunningham described an analogy as;
Shipping first-time code is like going into debt. A little debt speeds development so long as it is paid back promptly with a rewrite.
and explained the technical debt as a trade-off between producing clean code at a greater cost and later delivery vs writing inattentive code quickly and cheaply without considering the expense of more maintenance work after it is released.
It is dangerous to think that quick wins of building complex ML-based prediction systems as coming for free
The technical debt for Machine Learning(ML) systems exists at the system level instead of the code level, therefore, the traditional approach in technical debt as in software development is not enough and ML-specific approaches need to be discussed.
System-level in machine learning refers to the overall architecture and design of a machine learning system, as opposed to the individual components such as the algorithms or the data. This includes things like the system’s scalability, performance, robustness, and maintainability.
From a system-level perspective, it involves the integration and orchestration of various components such as data pipelines, storage, computation, and serving infrastructure. It also includes the design choices related to the deployment of the machine learning model, such as whether to deploy it on-premises, in the cloud, or at the edge. From the system-level perspective, the ML system may cause abstraction boundary erosion, or the used ML packages may result in large masses of glue code which can lock the system or the data influence the ML system in changing real-world conditions.

Complex Models Erode Boundaries
Friedrich Hayek described abstraction as “They are a means to cope with the complexity of the concrete which our mind is not capable of fully mastering.” in 1973, it also abstraction helps us to create more maintainable codes in terms of improvements and fixes. Even though the strict abstract dependencies are useful for consistent software system performance, it is not suitable for ML systems,
ML is required in exactly those cases when the desired behavior cannot be effectively expressed in software logic without dependency on external data.
Entanglement
A machine learning model consists of complex relations between features of the sample data, it entangles all the features. Using related features called feature selection or selecting suitable objective function is another case but, building those useful relations make ML model powerful but also makes ML models unsuitable for isolated improvements.
CACE principle: Changing Anything Changes Everything. CACE applies not only to input signals, but also to hyper-parameters, learning settings, sampling methods, convergence thresholds, data selection, and essentially every other possible tweak.
There may be two strategies for handling entanglement. One is isolating models as subtasks or sub-models and serving all the systems consisting of sub-models as ensembles. The other is observing changes in output behavior as they occur and applying an automated development strategy.
Correction Cascades
Sometimes two tasks are similar to each other but a slight modification is required and in that case, one ML model can be fed from another model’s output in order to solve the problem easily. However, that situation results in a problem in which one ML is strongly dependent on another. Also, the hidden cost is increased if there are more and more models in the cascaded ML system.
The suitable strategy in that scenario is adding additional features to the base model in order to use a simple model which is able to distinguish among cases.
Undeclared Consumer
Let’s start with an example. In an energy company, one data analysis team was working on a weather temperature prediction system. They have built the ML model that predicts the temperature successfully and they have deployed a system where the output is automatically inserted in a database that everyone in that company can access. They have done that because they know other teams are trying to develop an energy forecasting model therefore they can use the outputs of their weather temperature prediction system. Up to that point, the idea is simple and useful.
The problem starts here if there is some teams use those outputs for any other crucial tasks. Let’s say another in the same company uses those temperature predictions to give insight into a data center in order to schedule their operations. In that case, the cost of improvements in the temperature prediction model would be more costly than expected. The latter team is an undeclared consumer.
In more classical software engineering, these issues are referred to as visibility debt
The possible solution for the cases like that is giving access permission to particular teams that are allowed to reach a model and managing those permissions carefully.

Data Dependencies Cost More than Code Dependencies
Dependency debt is noted as a key contributor to code complexity and technical debt in classical software engineering settings.
In the paper, it is stated that the data dependencies in ML systems have a similar capacity for building debt and it is more difficult to detect.
Unstable Data Dependencies
ML systems are being fed by signals but some of the input signals may be unstable, in other words, they can change over time. That situation can happen when the signal is generated by another ML system that updates itself over time or comes from a data-dependent lookup table. Therefore obviously a mutation in the signal will be harmful to the consumer ML system which is trained by the original signals.
Versioning the given signal is the solution for the data dependency problem but that solution has another cost in itself, which is the storage cost. The versioning strategy should be such as, the original version of the signal should be stored while creating the mutated version until all the mutated versions have been observed and tested in all systems.
Underutilized Data Dependencies
Feature selection is the alchemy of ML model building. Using various features may cause explosions but sometimes humble ingredients can improve our model’s performance a little. As mentioned before, an ML model entangles all the features and that situation makes ML vulnerable to small changes in the signals.
There are various types of underutilized data dependencies. Legacy Features: A feature is useful in training but over time it becomes irrelevant to the prediction but affects the prediction. Bundle Features: this that means in the fast experiments multiple features have been added to the model but some of the features in the bundle are irrelevant. e-Features: sacrificing the model’s vulnerability for a little improvement in the accuracy by adding features. Correlated Features: using features which has a correlation between them and that makes the model to be brittle since the model may pick the non-causal feature or it may judge those features equally.
Underutilized dependencies can be handled by using leave-one-feature-out (LOFO) evaluations. That approach experimentally finds the relevant and useful features and selects them. There is a Python module for the LOFO approach: lofo-importance.
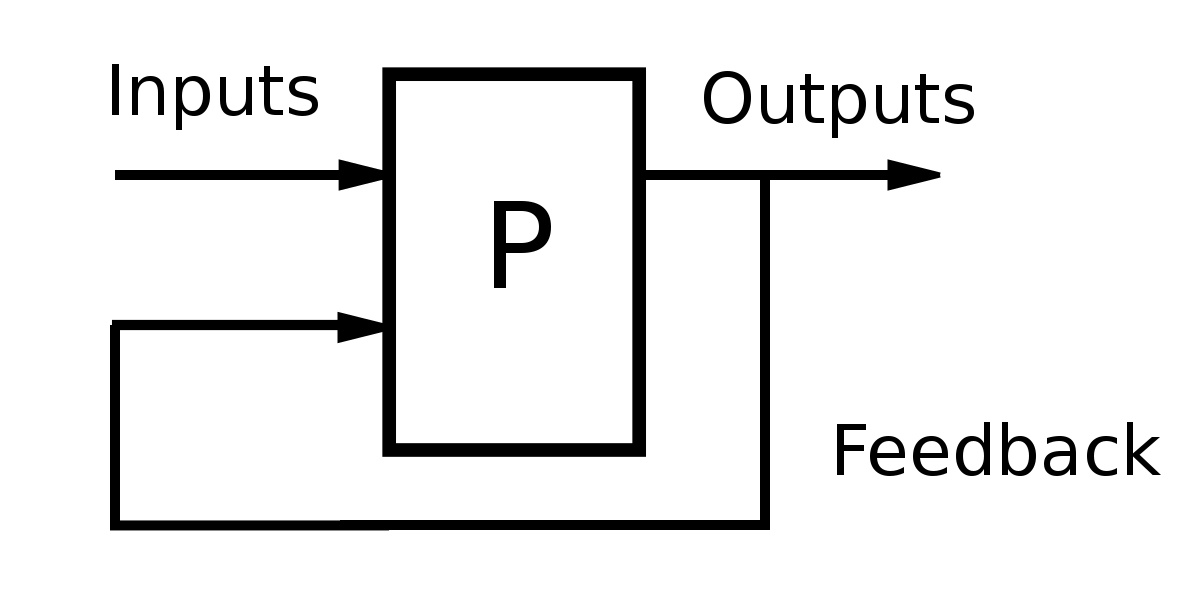
Feedback Loops
It is useful and beneficial to update the model over time and you can make the model influence itself over time for example feeding the feature selection step with the performance of the model. But that comes with a hidden debt called analysis debt which means you can not assume the behavior of the system before release.
The feedback loops come in two formats, direct and hidden feedback loops. Direct feedback loops refer to the example I have given in the beginning. These loops directly influence the model’s own behavior. The problem here is about the reinforcement learning models where you not only optimize decisions based on previous observations, but you also personalize decisions for every situation and that approach does not scale well to the size of action spaces. To handle that problem, one can use randomization or isolate some parts of the data from being influenced.
On the other hand, hidden feedback loops mean that the two separate systems influence each other in a hidden way. What I mean is one’s output can change the environment or one’s output might be used by other models.

ML-System Anti-Patterns
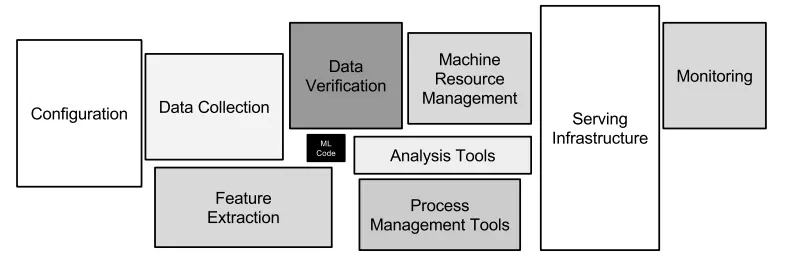
Only a tiny fraction of the code in many ML systems is actually devoted to learning or prediction
Anti-patterns in ML systems are common mistakes or suboptimal solutions that arise during the design and development process. These can lead to poor performance, increased development time, or other negative consequences
Glue Code
Glue code is a type of code block that acts as a connector between various software or libraries/packages. From an ML perspective, the glue code is used to connect models, ETL pipelines, and other parts of a system. Even though it looks useful for ML systems, it results in a massive amount of supporting codes and that can lock the system because of the dependencies of the used package. Using those generic packages also can prevent us from improvements because it makes it harder for us to make small modifications without considering the package’s limits. One useful solution is wrapping black-box packages into API in a way that we can reuse the same functions and configure them for our limited needs.
A mature system might end up being (at most) 5% machine learning code and (at least) 95% glue code, it may be less costly to create a clean native solution rather than re-use a generic package.
Pipeline Jungles
Developing systems as pipelines is beneficial for deployment from end to end. Pipeline jungles usually appear in ETL pipelines and data preparation. Testing those pipelines requires expensive end-to-end integration tests. These jungles can be handled by considering data gathering and feature engineering steps as joint firstly. And then the jungle pipeline should be investigated and redesigned from the ground. That approach has another engineering cost but when the long-term hidden cost is taken into account, it is worth investing.
Dead Experimental Codepaths
You know, we all are developers and love to experience different approaches or we want to test while coding. The dead experimental codepaths occur right here when we want to perform alternative methods in the short term. Sometimes that experiments leave lines of experimental codes in the main production code. For a highly dependent ML system, it becomes costly to make changes in the infrastructure.
There is an example in the paper, I have searched for it for you guys;
Two significant technological errors committed by Knight Capital contributed to the trading incident on August 1, 2012. In 2005, Knight Capital relocated a portion of computer code in an automated equity router to an earlier position in the coding sequence, breaking the router’s functionality. Knight left this function in the router even though it wasn’t intended to be utilized. Due to this, some NYSE-eligible orders caused Knight Capital’s router to malfunction, making it impossible for the router to determine whether an order had been filled. When trying to fill just 212 customer orders on August 1 during the first 45 minutes of the market’s opening, Knight Capital’s router quickly sent more than 4 million orders into the market, and eventually suffered a loss of more than US$460 million.
To handle that issue, it is useful to reinvestigate each part of the code especially experimental branches to find which parts can cause workload and those parts can be abandoned.
Abstraction Debt
The above issues highlight the fact that there is a distinct lack of strong abstractions to support ML systems.
In the paper, it is stated that nothing in the machine learning literature comes close to the success of the relational database as a basic abstraction.
Common Smells
Messy or unclean coding has been referred to as having a “smell” which indicates that there is some of the code that has to be cleaned up for the future. There are a couple of smell types classified by the authors of the paper;
-
Plain-Old-Data Smell: A ML system should be aware of the types and features of its input and output variables.
-
Multiple-Language Smell: Usually particular steps in an ML pipeline may have different languages or syntaxes. That situation often results in an additional cost for maintaining and testing the system.
-
Prototype Smell: Prototypes are beneficial for system testing. The prototyping environment has its own cost when it comes to maintaining it but the crucial mistake is using that environment as production under time pressure.

Configuration Debt
ML systems come with lots of configurable parameters such as learning parameters, how many features should be selected in the feature engineering part or how the data will be transformed etc. In the paper, it is stated that the authors observed that both researchers and engineers may treat configuration as a post-process. The number of configurations can be unexpectedly high when it comes to verification and each of them has its own potential failure, which means cost, loss of time, waste of computing resources also most importantly, in my opinion, production issues.
The authors proposed a couple of principles for a good configuration system;
-
It should be easy to specify a configuration as a small change from a previous configuration.
-
It should be hard to make manual errors, omissions, or oversights.
-
It should be easy to see, visually, the difference in configuration between the two models.
-
It should be easy to automatically assert and verify basic facts about the configuration: the number of features used, the transitive closure of data dependencies, etc.
-
It should be possible to detect unused or redundant settings.
-
Configurations should undergo a full code review and be checked into a repository.

Dealing with Changes in the External World
Dealing with datasets and building ML models are funny and fascinating. However, in the real-world jungle problems are more predatory and they change over time. The real world is rarely stable. This results in ongoing maintenance costs and somehow those costs can be reduced with a couple of precautions.
Fixed Thresholds in Dynamic Systems
Thresholds are everywhere. One can use a specific threshold value to identify the outliers and that may work at the time of the development. But the distribution of the data can be changed over time system with a fixed threshold value would make wrong predictions. These threshold values are set experimentally, so a basic strategy would be updating threshold values dynamically by simple evaluations.
Monitoring and Testing
You should always test your system, code, model, or whatever before deploying it. Testing of particular parts of a running system is worthy but that test can not ensure that the system is working properly for every condition. At that point, monitoring is a good solution in order to observe the real-time changes in different metrics and behaviors. So the question is “What to monitor?”
-
Prediction Bias: The distribution of predicted labels should be equal to the distribution of the observed labels. But when real-world behavior starts to change, prediction of the systems may break that rule. Usually, monitoring the bias very information for taking action.
-
Action Limits: The ML systems could be informative to take actions or they could take actions themselves. Since those actions are taken in the real world, there must be some limitations in terms of action limits. When the actions reached those limits, alerts should be fired and the action should be canceled.
-
Up-Stream Producers: Some of the ML systems are being fed by upstream producers. Therefore, upstream producers’ processes should be monitored in terms of the objectives of the whole system including upstream and downstream systems.
Long short story,
Creating systems that allow automated response without direct human intervention is often well worth the investment.
Other Areas of ML-related Debt
An ML system’s pipeline contains a variety of steps, from data collection, feature engineering, and model training to deployment and monitoring. In some of those steps and related areas, technical debt may occur.
Data Testing Debt. Testing and monitoring the properties of the data used as input is important and useful for ML systems since those systems highly rely on the data. Reproducibility Debt. While experimenting with the ML systems it is important to take similar results in each test but in real-world environments that can be difficult. Process Management Debt. The cost of maintaining a mature system is very high since in such a system there are hundreds of ML models. As developers, we should be able to design a system that automatically recovers itself by automating manual steps. Cultural Debt. The team is everything, every team has to be on the same page in itself. A team should encourage developers, and scientists to be aware of all of those technical debts and should reward the improvements that can reduce the hidden cost.
Bottom Line
In that post, I reviewed and summarized the paper “Hidden Technical Debt of Machine Learning Systems” written by Sculley et al.
That paper and the perspective which is described in the paper are important for building maintainable, sustainable, reproducible ML systems. Of course, that perspective and actions come with a cost in a short time period but in long term, it saves teams from unexpected hidden costs and critical results. Therefore specialized testing monitoring developing techniques should be applied without running a rush, otherwise, hidden technical debt occurs.
In my opinion, we should be aware of every step of an ML system pipeline and assume it holistically. It would be a good perspective to looking an ML system as a live thing that needs to be investigated and monitored in its lifetime. But before doing that the system should be built meticulously and delicately by considering every consequence and being patient.