Neural Architecture Search (NAS) - Review, Research
16 Mar 2023Businesses need neural architecture search (NAS) and automated machine learning (AutoML) to automate the process of designing and optimizing machine learning models. NAS can help businesses to save time and money by automatically discovering network architectures that are optimized for their specific use case. AutoML can further automate the machine learning process by automatically selecting the best algorithm, preprocessing steps, hyperparameters, and other model components. This can lead to better performance, more efficient use of resources, and faster time-to-market for machine learning applications. Additionally, NAS and AutoML can help businesses to keep up with the rapid pace of advancements in artificial intelligence and machine learning by quickly adapting to new requirements and datasets.
As a result, research has turned to developing algorithms for neural architecture search (NAS) in order to find effective new architectures that perform well without requiring human expertise.
AutoML and NAS
The majority of machine learning problems, including computer vision, speech recognition, and machine translation, highly rely on deep learning. The progress in this field has been driven by the discovery of new neural network architectures, which has usually been the work of machine learning researchers/engineers or more basically AI-expert teams. Exploration and evaluation of new neural network architectures are very time-consuming and require knowledge and effort. To overcome that problem and automate the exploration pipeline two major concepts have been revealed; Neural Architecture Search (NAS) and Automated Machine Learning (AutoML). Both NAS and AutoML automate the process of designing and optimizing machine learning models by automatically selecting the best algorithm, preprocessing steps, hyperparameters, and other model components. Additionally, NAS and AutoML can help businesses to keep up with the rapid pace of advancements in artificial intelligence and machine learning by quickly adapting to new requirements and datasets.
What is NAS?
AutoML has become a very important research topic since it enables people with limited machine learning background knowledge to use machine learning models easily. In the context of deep learning, and actually also as a subtopic of AutoML, NAS aims to search for the best neural network architecture for the given learning task and the dataset has become an effective computational tool in the field.

In a neural architecture there are multiple factors to consider such as the architecture itself, hyperparameters, and training parameters, and finding the most suitable model configuration requires lots of time and resources. Therefore an efficient NAS algorithm would be life-saving for practitioners.
The general problem was formulated in AutoKeras paper as follows; for a given search space $\mathbb{F}$, the input data $\mathbb{D}$ divided in $\mathbb{D_{train}}$ and $\mathbb{D_{val}}$, and the cost function $Cost(.)$, we aim at finding an optimal neural network $f^* \in \mathbb{F}$, which could achieve the lowest cost on dataset $\mathbb{D}$. The definition is equivalent to finding $f^*$ satisfying:
\[f^* = \underset{f \in \mathcal{F}}{ \arg\min} Cost(f(\theta^*), \mathcal{D_{val}}) \\ \theta^* = \underset{ \theta }{\arg\min}\mathcal{L}(f(\theta), \mathcal{D_{train}})\]where $Cost(.,.)$ is the evaluation metric function, e.g. accuracy, means squared error, $\theta^*$ is the learned parameter of $f$.
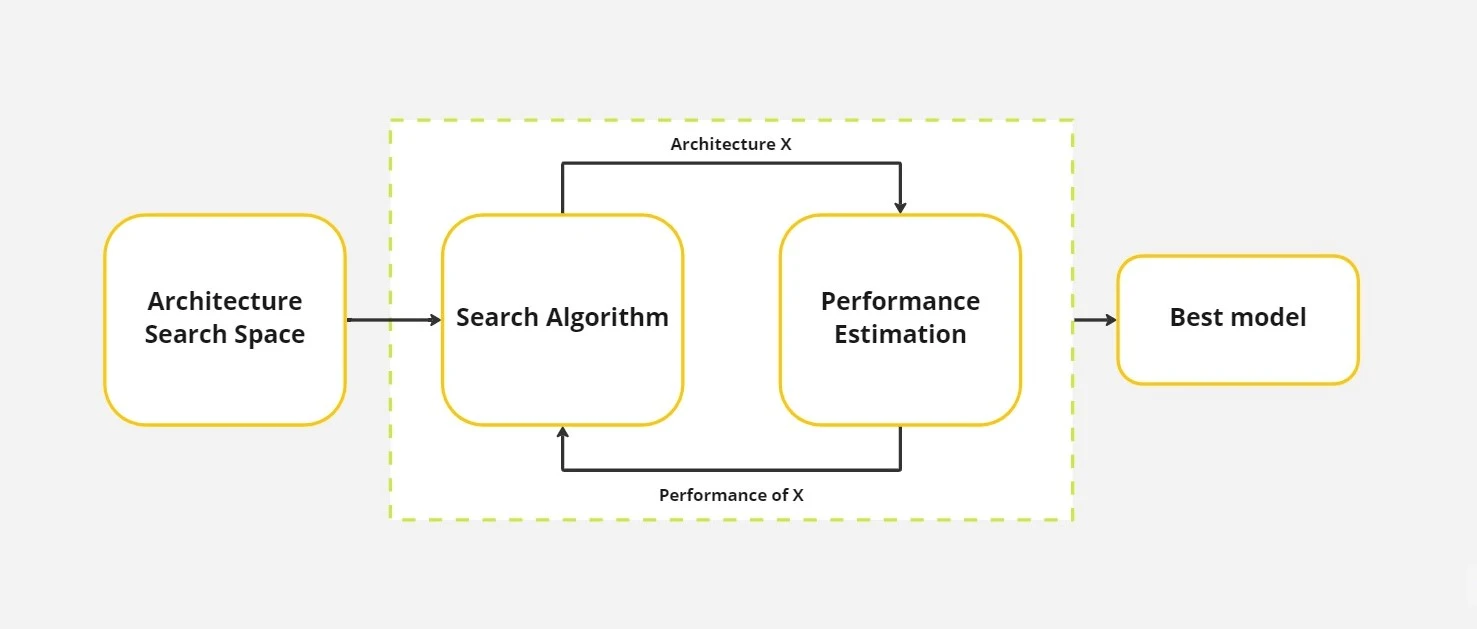
Basically, there are 3 steps in the NAS process; architecture search space, search algorithm, and performance estimation.
-
Architecture Search Space. The primary goal of NAS is founding the best architecture therefore it is required to define lots of architectures and configurations in order to evaluate and select the best one. A basic approach could be defining thousands of models and configurations and evaluating each of them. That works if you have unlimited time, money, and patience… And also introduces a human bias.
-
Search Strategy. Let’s say we have built a useful search space that contains different architectures with a range of configurations which can lead the search algorithm to find a model that can overperform sota models. But the question is how we can effectively explore a search space to find the best architecture. It incorporates the traditional exploration-exploitation trade-off because, while it is desired to locate effective architectures fast, it is also advisable to prevent premature convergence to an area of inferior architectures.
-
Performance Estimation Strategy. Another definition of the goal is to find architectures that achieve high predictive performance. In order to evaluate the performance one strategy can be standard training and validation of the architecture on data, but this is costly. Recent research, therefore, focuses on developing methods that reduce the cost of these performance estimations.
Researches
Neural Architecture Search with Reinforcement Learning (Zoph et al., 2016)
Neural Architecture Search with Reinforcement Learning(RL) is one of Google Brain’s research in the field of AutoML. The authors proposed a model construction strategy with Recurrent Neural Networks(RNN) and used RL to maximize the expected accuracy on the validation dataset.
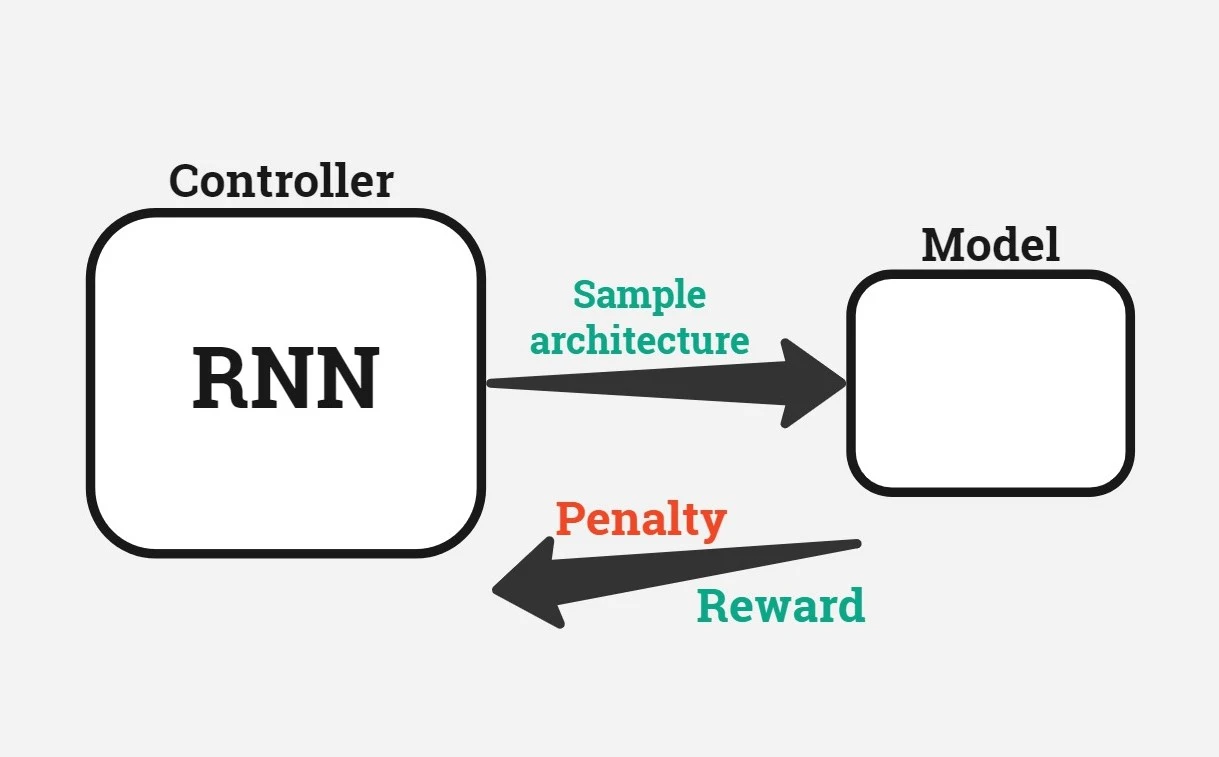
Basically, RNN is proposing a new network architecture by acting as a sequence generation task. If the generated model performs well controller gets a reward otherwise gets penalized, which is the standard learning mechanism in RL. Controller learns expected validation errors and proposes better architecture in further iterations, and learns what direction to explore next.
RL is okay, fair, and logical enough but how the network generation with RNN works? Computations for basic RNN and LSTM cells are generalized as a tree of steps that take inputs as the output and the hidden state of the previous time step to generate the current hidden state. RNN labels each node in the tree with a combination function (addition, elementwise multiplication, etc.) and an activation function (tanh, sigmoid, etc.) to merge two inputs and produce one output.
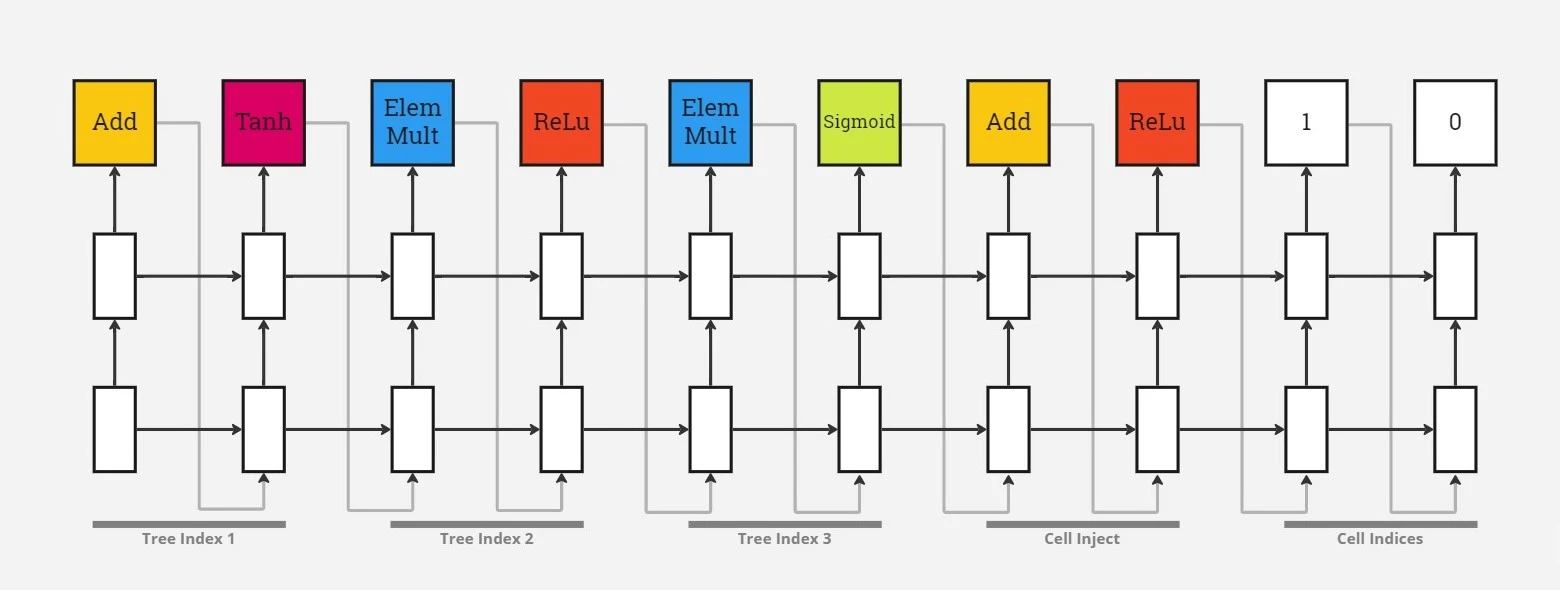
On the CIFAR-10 dataset, the proposed model by the RNN and RL-powered NAS method has achieved a test error rate of 3.65, which is 0.09 percent better and 1.05x faster than the previous state-of-the-art model. But, this method is very computationally expensive; they have used 800 GPUs and the process has lasted 28 days. HUGE.
Learning Transferable Architectures for Scalable Image Recognition (Nasnet) (Zoph et al., 2018)
As generating a network that is specific to a dataset of interest is expensive when the dataset is large, they have proposed to search for an architectural building block on a small dataset and then transfer the block to a larger dataset. The critical contribution of the method is the design of a new search space (which is called “NASNet search space”) that enables transferability.
The main search method relies on the RL and the previous work that we mentioned above. However, the main contribution to the work is the building strategy of the networks. They said that they have realized there are certain motifs in the architecture engineering with CNNs which consists of combinations of convolutional filter banks, nonlinearities, and selection of connections. Therefore, they have defined two types of layers/cells that can serve two main functions;
-
Normal Cell: Convolutional cells that return a feature map of the same dimension
-
Reduction Cell: Convolutional cells that return a feature map where the feature map height and width are reduced by a factor of two.
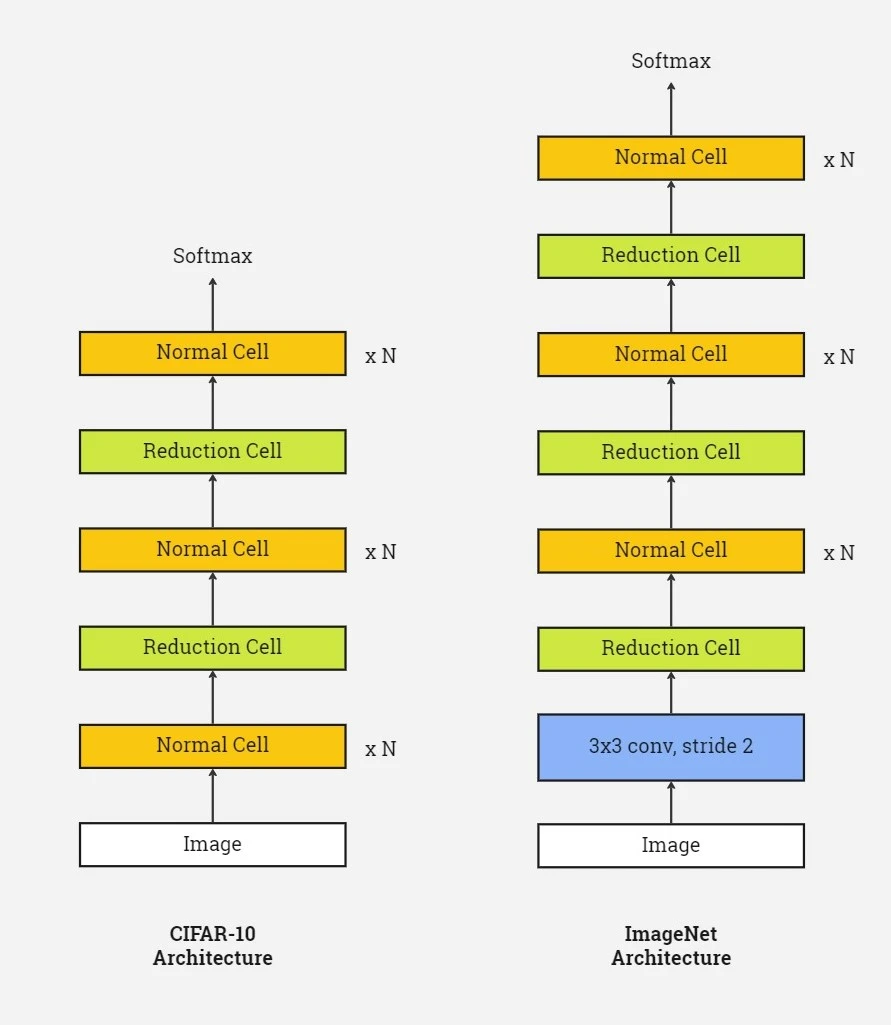
In the RNN part, there is 5 steps while selecting the new layer type, Normal Cell or Reduction Cell (you can check the paper for those steps). As you can see in the figure above, there is a 3x3 convolutional layer that we didn’t mention before. In order to feed the RNN with an initial hidden state, the algorithm selects an operation to apply the initial hidden state from a set of hidden states.
In the experiments, they used 500 GPUs and the search process lasted 4 days which is 7x better than the previous approach.
Efficient Neural Architecture Search via Parameter Sharing (ENAS) (Pham et al., 2018)
In this work, they have developed an approximation of NASnet but an efficient one, therefore they called it Efficient NAS(ENAS). The idea behind that the network architectures include similar sub-architectures that look identical and in that case, those sub-architectures, in other words, child models, can share the same parameters, and weights as an approximation.
In the ENAS, parent, and child models are not trained from scratch, the parent model forces a child with the same architecture to share weight and the parent one is built and evaluated with that child model and weights. Once, the best model architecture is found, the final model is trained from zero.
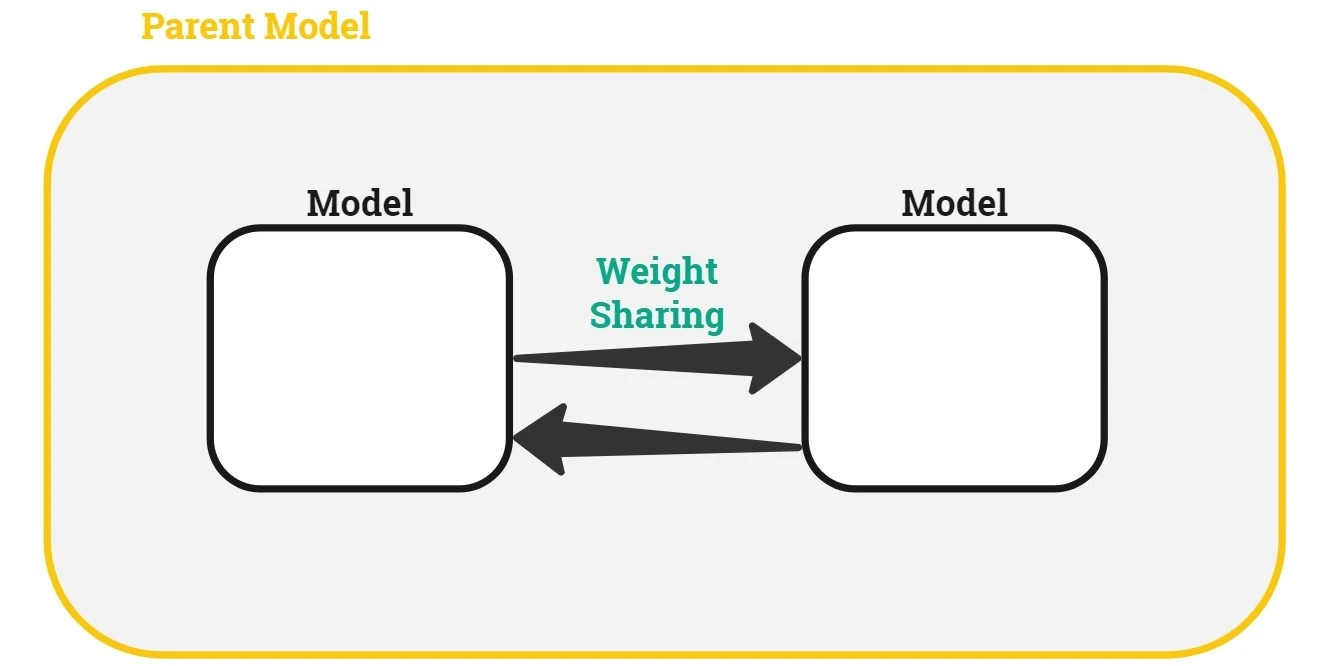
ENAS produces good results as NASNet with only 1 GPU and less than 16 hours.
Efficient Multi-objective Neural Architecture Search via Lamarckian Evolution (LEMONADE) (Elsken et al., 2018)
LEMONADE is the first evolutionary algorithm in our list. The idea behind the proposed method is the fact that there is typically an implicit trade-off between predictive performance and consumption of resources. Therefore authors have proposed an evolutionary algorithm called LEMONADE, for multi-objective architecture search that allows approximating the entire Pareto front of architectures under multiple objectives.
LEMONADE aims to minimize multiple objectives where the first components denote expensive-to-evaluate objectives (such as the validation error or some measure only obtainable by expensive simulation) and its other components denote cheap-to-evaluate objectives (such as model size) that one also tries to minimize.
Auto-Keras: An Efficient Neural Architecture Search System (Jin et al., 2019)
There is our lovely friend, Keras. They have developed an open-source AutoML package called Auto-Keras based on their proposed approach and the Keras we know.
In the paper, the proposed method uses Bayesian optimization to guide the network morphism for an efficient NAS. The framework develops a neural network kernel and a tree-structured acquisition function optimization algorithm to efficiently explore the search space.
Since the Bayesian optimization is not suitable for tree-structured search space, researchers proposed a couple of approaches to tackle multiple problems;
-
An edit-distance neural network kernel is constructed.
-
A new acquisition function to use BO in tree-structured search via network morphism.
-
A graph-level network morphism is defined to address the changes in the neural architectures based on layer-level network morphism.
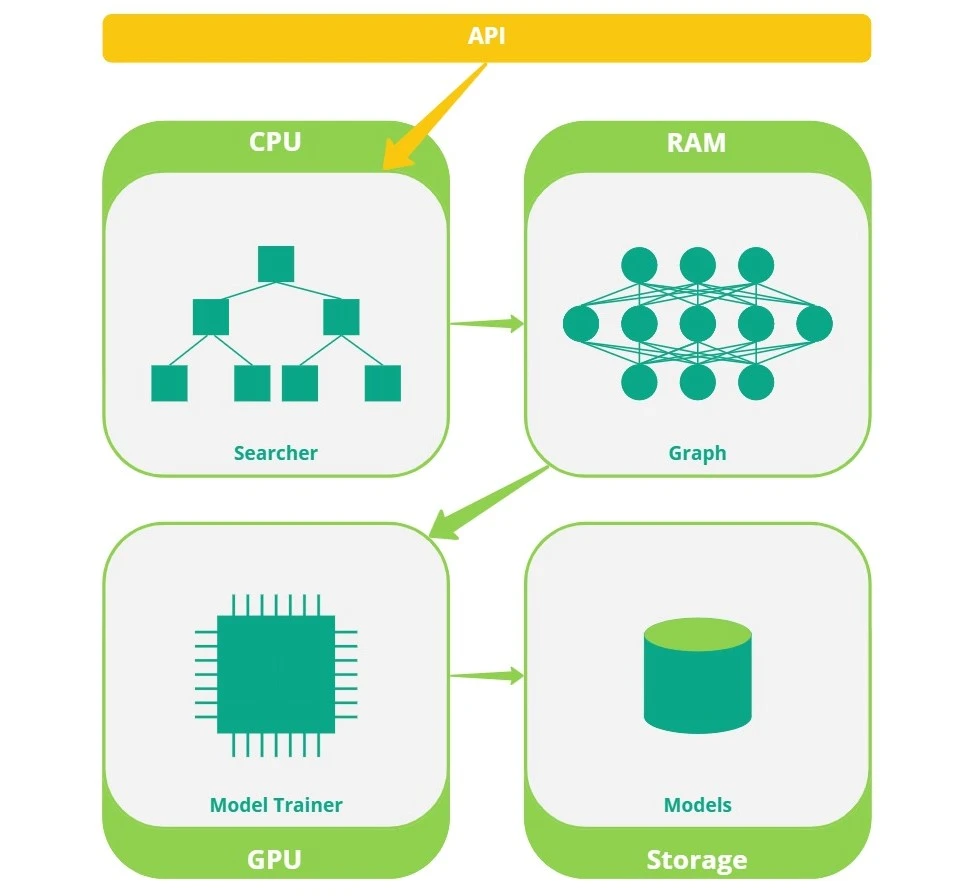
They also spread their algorithm to different storage levels for efficient use of computational resources.
DARTS: Differentiable Architecture Search (Liu et al., 2018)
This method uses neither reinforcement learning nor evolutionary algorithms. The method is based on the continuous relaxation of the architecture representation, they suggested using a technique called DARTS (Differentiable ARchiTecture Search) for effective architecture search.
Basically, the computation procedure for architecture in the search space is represented as a directed acyclic graph where each node is a latent representation and each directed edge is associated with some operation.
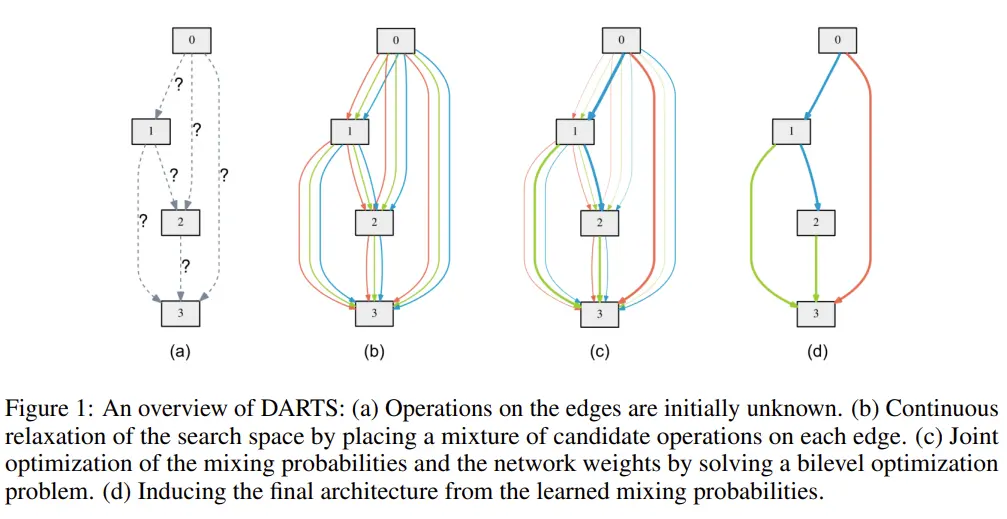
They relaxed the search space to be continuous rather than searching across a discrete collection of candidate architectures. So that the architecture might be optimized via gradient descent with regard to the performance of the validation set. After relaxation, the goal is to jointly learn architecture and the weights within all the mixed operations.
Auto-PyTorch Tabular: Multi-Fidelity MetaLearning for Efficient and Robust AutoDL (Zimmer et al., 2020)
As the name suggests, Auto-PyTorch relies on the PyTorch framework, another lovely fella. Auto-PyTorch is an AutoML framework targeted at tabular data that performs multi-fidelity optimization on a joint search space of architectural parameters and training hyperparameters for neural nets.
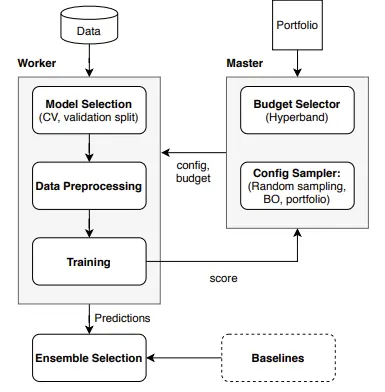
There are several hyperparameters in the configuration space offered by Auto-PyTorch Tabular, including preprocessing options (such as encoding, imputation), architectural hyperparameters (such as network type, number of layers), and training hyperparameters (e.g. learning rate, weight decay).
There are two configuration spaces: (i) a small space with only a few key design choices, allowing for a thorough, quick, and memory-efficient study; and (ii) the entire space of Auto-PyTorch Tabular, allowing for cutting-edge performance.
It can be difficult to achieve good anytime performance with DNNs because training them can be expensive. To address this, Auto-PyTorch uses a multi-fidelity optimization strategy, employing BOHB to identify configurations that perform well over a range of budgets. Bayesian optimization (BO) and Hyperband are combined in BOHB (HB).
Auto-PyTorch Tabular performs better than several other common AutoML frameworks: Auto-Keras, AutoGluon, and auto-sklearn.
Meta-Learning of Neural Architectures for Few-Shot Learning (MetaNAS) (Elsken et al., 2019)
The goal of meta-learning is to meta-learn an architecture with corresponding weights which is able to quickly adapt to new tasks. In terms of NAS, meta-learning works by training a meta-model on a variety of tasks that are relevant to the target task of identifying the best possible neural architecture.
In this work, the focus is on few-shot learning, the problem of learning a new task with limited training data. Authors extended the model agnostic meta-learning approaches such as REPTILE, which only can employ a simple CNN. In MetaNAS, the task-learning algorithm, called gradient-based meta-learner, optimizes both initial task weights and task architecture. They used REPTILE, which is used for fixed architecture, for both meta-learning the set of weights and also incorporated REPTILE with DARTS in order to extend the architecture itself.
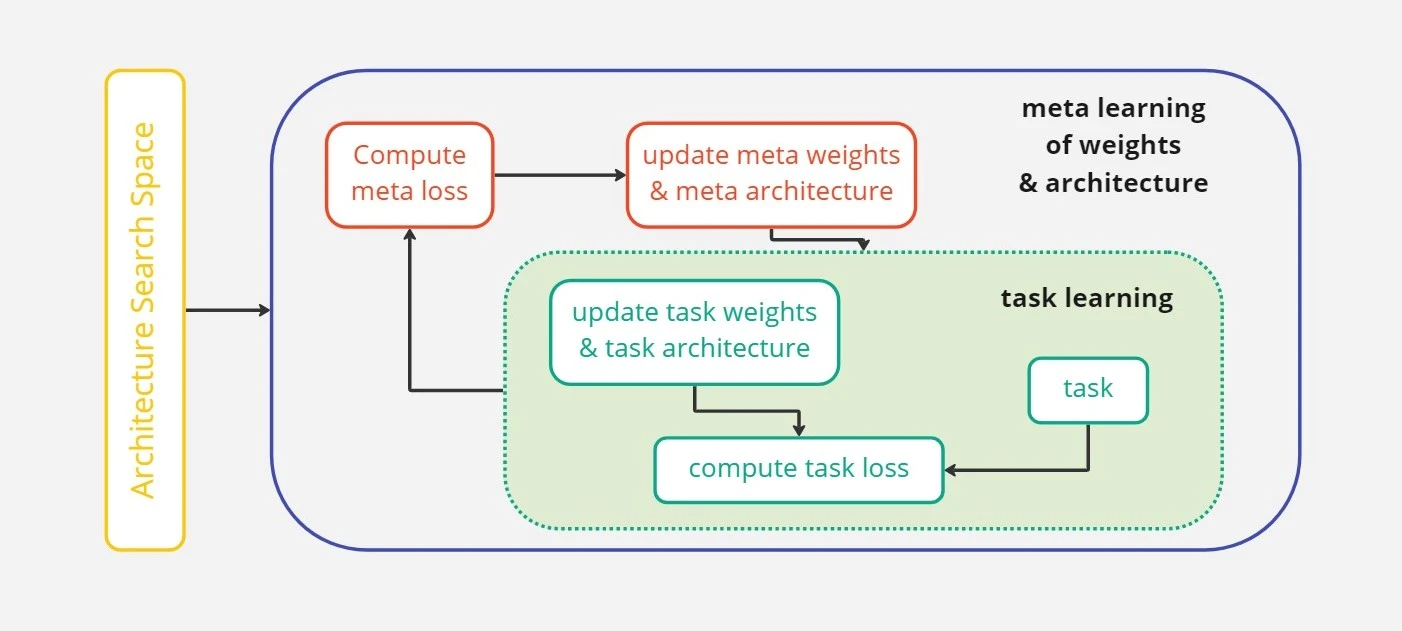
The performance of new architectures can therefore be predicted using this meta-model to direct the search process without having to train them from start. Only promising architectures are chosen for further examination, which makes the search process more effective.
Rapid Neural Architecture Search by Learning to Generate Graphs from Datasets (MetaD2A) (Lee et al., 2021)
The interesting thing in the proposed method, MetaD2A (Meta Dataset-to-Architecture), is there is an encoder-decoder approach with a set encoder and a graph decoder which is used to learn a latent space for datasets and neural architectures. The built framework is fed by a prepared dataset containing datasets and their corresponding neural architectures. Meta-trainer learns the optimum architecture for given datasets from the database by encoding the dataset to create the latent space representation.
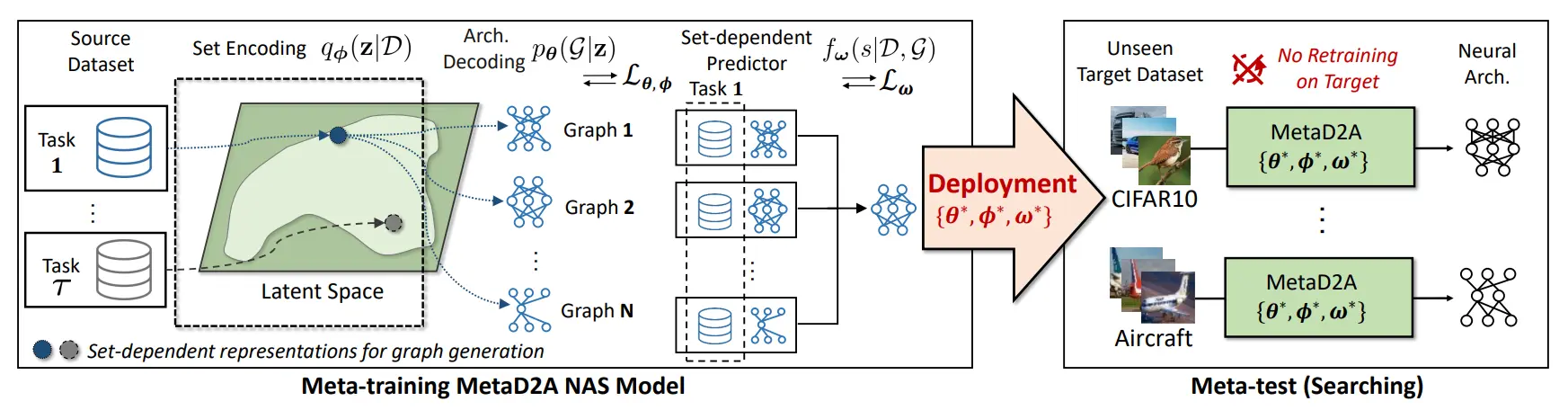
For a new dataset, MetaD2A stochastically generates neural architecture candidates from latent representations, which are encoded from a new dataset, and selects the final neural architecture based on their predicted accuracies by a performance predictor, which is also trained with amortized meta-learning.
Primer: Searching for Efficient Transformers for Language Modeling (So et al., 2021)
Decoder-only designs, as those in the GPT, immediately ingest the input text prompt and output the most probable sequence of text tokens. The proposed method, Primer, in the paper, uses evolutionary search on a decoder-only search space for auto-regressive language modeling (LM) tasks. The goal is that the reducing the cost of searching for an efficient Transformer variant.
NAS-BERT: Task-Agnostic and Adaptive-Size BERT Compression with Neural Architecture Search (Xu et al., 2021)
The paper presents NAS-BERT, a method for conducting neural architecture searches to find small, accurate, and novel BERT models. The goal of the method is to ensure that the resulting models can be deployed on different devices with varying memory and latency constraints, and can perform well on different downstream tasks. To achieve this, the authors trained a supernet with a new search space that contains models of different sizes, and then directly searched for models on the pre-training task to make them more generalizable to downstream tasks. NAS-BERT is a nice approach for finding optimized BERT models that can be used across a range of applications and devices.
Bottom Line
I think the field of NAS is very interesting and exciting since the variety of techniques proposed to find the most suitable neural model. NAS automates the design of neural networks, saving time and resources which also makes the field exciting too. In my opinion, NAS will transform the field of deep learning and open up exciting new possibilities for applications in a range of industries. Whether you are a researcher, developer, or data scientist, NAS has the potential to help you create more efficient and accurate neural networks for your specific use case.
Resources
📄 Neural Architecture Search with Reinforcement Learning (Zoph et al., 2016)
📄 Learning Transferable Architectures for Scalable Image Recognition (Zoph et al., 2018)
📄 Efficient Neural Architecture Search via Parameter Sharing (Pham et al., 2018)
📄 Efficient Multi-objective Neural Architecture Search via Lamarckian Evolution (Elsken et al., 2018)
📄 Auto-Keras: An Efficient Neural Architecture Search System (Jin et al., 2019)
📄 DARTS: Differentiable Architecture Search (Liu et al., 2018)
📄 Meta-Learning of Neural Architectures for Few-Shot Learning (Elsken et al., 2019)
📄 Rapid Neural Architecture Search by Learning to Generate Graphs from Datasets (Lee et al., 2021)
📄 Primer: Searching for Efficient Transformers for Language Modeling (So et al., 2021)
📄 Neural Architecture Search: Insights from 1000 Papers (White et al., 2023)
📄 Neural Architecture Search: A Survey (Elsken et al., 2019)
▶ YouTube - Leo Isikdogan - Network Architecture Search: AutoML and others