Introducing Network-Aware Federated Neural Architecture Search
26 Jan 2026I’ll be honest: I meant to write this blog post shortly after our 2025 publication. But as it turns out, just like the high-latency networks we studied, my own ‘packet delivery’ got a bit delayed. Better late than never—especially since the industry is still struggling with the exact bottlenecks we highlighted in the paper.
About This Work
I am excited to share our research paper, “Network-aware federated neural architecture search” which was published in the Future Generation Computer Systems.
In this work, we argue that you cannot optimize AI for the edge without explicitly optimizing for the network conditions it runs on. We developed a comprehensive open-source framework that balances model performance, communication efficiency, and network constraints simultaneously.
Motivation
Moving AI from centralized data centers onto the edge and IoT devices enables real-time AI applications but also it introduces a massive challange: how do we design powerful AI models that fit on resource-constrained devices without compromising user privacy?
Usually, we rely on two distinct technologies to solve this: Neural Architecture Search (NAS) to automate the design of efficient models, and Federated Learning (FL) to train them collaboratively (collaboration of edge devices) without ever moving the raw data.
However, there is a critical element that often gets overlooked: The Network.
In a real-world FL system, network limitations—like low bandwidth or high latency—can lead to biased model training, slower convergence, and massive communication bottlenecks. If a client has a poor connection, they might drop out or delay the whole process, skewing the results.
Invisible Bottleneck in Distributed AI
We do not problems with that AI models are running on huge centralized data centers. However, when the real-time inference or data sensitivity matters for an AI application, computation is moving to the edge side.
Running AI on the edge offers three massive benefits:
- Low Latency: Decisions are made instantly on the device.
- Bandwidth Optimization: We don’t need to send terabytes of raw data to the cloud.
- Privacy: Personal data remains on the user’s device.
But, how we can fit modern DNNs that are massive and complex to ting devices which have limited batter and processing power without sacrificing privacy?
Federated Learning (FL) and Neural Architecture Search (NAS)
To solve this, researchers combine two powerful technologies. In our paper, we leverage both to create a system that is efficient in terms of both computation and communication.
Federated Learning (FL): The Privacy Shield
Proposed by Google in 2016, Federated Learning allows devices to train a shared global model collaboratively without ever sharing their raw data.

- The server sends a model to clients (4). Clients train it on their local data (1) and send only the weight updates back to the server (2). The server aggregates these updates (3) (usually averaging them) to improve the global model.
Neural Architecture Search (NAS): Automating Efficiency
Manually designing a neural network that is small enough for a phone but smart enough to be useful is incredibly difficult and requires expert engineering.
- NAS automates the design process. It searches through thousands of possible architectures to find one that maximizes accuracy while minimizing computational cost.
- Our Focus (Pruning): We specifically focus on Neural Network Pruning. This is a technique where we take a large model and systematically remove redundant connections (weights) or entire components (filters). The result is a lightweight model that runs faster and consumes less energy.
Why the “Network” is the Missing Link
While FL and NAS are powerful, most existing research ignores a critical factor: The Network itself.
In a theoretical lab setting, we might assume all devices have fast, stable internet connections. In the real world, this is rarely true.
- Network Heterogeneity: Some clients are on high-speed Wi-Fi, while others are on spotty 4G connections. In standard FL, the system often has to wait for the slowest device, creating massive bottlenecks.
- Biased Training: If a client has a bad connection, they might drop out or fail to send updates in time. This means the model never learns from that user’s data, leading to a biased model that only works well for users with good internet.

The NAFNAS Framework
I short, you cannot simply “copy-paste” NAS into a FL environment without accounting for the chaos of real-world networks.

To solve this, NAFNAS (Network-Aware Federated Neural Architecture Search) is an open-source framework that performs neural network pruning within a federated environment. Uniquely, it includes a network emulator to simulate real-world bandwidth fluctuations, allowing us to test how our system survives in poor network conditions. It is a comprehensive system that combines three distinct techniques to find the most efficient DL models while respecting the privacy and bandwidth constraints of edge devices.
The network emulator, emulates the bottlenecks in the network. NetDAG (Network and Distribution Aware Client Grouping) is a novel algorithm that solves the bottleneck problem. Instead of selecting clients randomly, NetDAG strategically groups them based on their bandwidth availability and their class distribution. This ensures that training is both fast (no waiting for slow clients) and fair (balanced data representation).
Our framework is built on a fusion of three critical components: a Neural Network Pruning Algorithm, a Federated Learning Framework, and a Network Emulator.
1. The Pruning Engine (Server-Side): NetAdapt
At the heart of our server is the logic that actually makes the AI models smaller. We utilize NetAdapt, a structured pruning algorithm known for its iterative approach.
AlexNet tries to find the perfect model in one go, the server works in rounds (iterations) of Block-Based Pruning. We use an AlexNet architecture divided into “blocks” (groups of layers). In each iteration, the algorithm proposes multiple “candidate” models by pruning filters from different blocks.
The system follows a resource reduction schedule. We define a target (e.g., reducing computational cost or “MACs”) and the algorithm shrinks the model step-by-step until it fits the constraints of the edge devices.

The FL Connection: Unlike standard NetAdapt which uses local GPUs, our framework distributes these candidate models to the clients. The clients fine-tune them on their private data, and the server picks the winner based on the aggregated accuracy.
2. The Federated Learning Infrastructure: Flower FL
To handle the communication between the central server and the edge devices, we integrated the Flower FL Framework. Flower allows us to build a scalable and secure pipeline using the gRPC protocol.

We had to customize the standard FL process for NAS:
-
Sending Architecture, Not Just Weights: In standard FL, the model structure stays the same. In NAFNAS, the structure changes every time we prune a layer. We configured the server to serialize the entire model architecture (using TorchScript) and send it to clients so they know exactly which “candidate” model they are training.
-
Federated Metric Aggregation: Since clients have different amounts of data, the server aggregates accuracy metrics (weighted by the number of samples) to fairly evaluate which pruned model is performing best.
3. The Network Emulator: CORE
This is where NAFNAS distinguishes itself from theoretical studies. We cannot assume every client has perfect 5G internet. To mimic reality, we incorporated CORE (Common Open Research Emulator).
- Real-Time Simulation: Unlike abstract simulations, CORE creates a real-time network environment. We run the FL clients inside Docker containers that act as distinct nodes in this emulated network.
- Dynamic Bandwidth: We programmed the emulator to change bandwidth conditions dynamically. Every 5 minutes, the bandwidth for each client fluctuates within specific “tiers” (e.g., Low, Medium, High). This allows us to stress-test how the system handles clients dropping from fast Wi-Fi to slow cellular connections.
Introducing NetDAG
Having a pruning engine and a network emulator is powerful, but it introduces a new problem: Bottlenecks.
If we randomly assign clients to train different candidate models, we might assign a massive model to a client with a tiny bandwidth connection. That single client will delay the entire training round. Furthermore, because data is Non-IID (heterogeneous), randomly grouping clients can lead to models that fail to generalize.
NetDAG is a novel client grouping algorithm designed to balance two competing objectives: Communication Efficiency and Data (Class) Balance. NetDAG strategically assigns specific clients to specific candidate models. It acts as a “matchmaker” inside the server, ensuring that the groups assigned to train each model are optimized for both bandwidth and data diversity.
Step 1: The “Network-Aware” Initialization
First, NetDAG looks at the bandwidth limitations. It categorizes clients into tiers (Low, Medium, High). It initially sorts clients and assigns those with the lowest bandwidth to the smallest pruned models.
Small models require less data transfer. By matching slow clients with small models, we minimize the risk of a communication bottleneck stalling the system.
Step 2: Measuring Fairness with Earth Mover’s Distance (EMD)
Once the initial groups are set, we need to check if the data is balanced. We use a metric called Earth Mover’s Distance (EMD), also known as Wasserstein distance.
\[EMD_k = \sum_{i=1}^C ||p_{y=i}^{(k)} - P_{y=i}||\]where $C$ denotes the number of class types, $p_{y=i}^{(k)}$ refers to the proportion of the number of the $i$th type data of client $k$ and $p_{y=i}$ refers to the global proportion.
Normally, EMD measures the “work” required to transform one distribution into another. In Our Context, EMD represents the distance between a client group’s class distribution and the global class distribution. A high EMD means the group is biased (e.g., too many of one class). A low EMD means the group is fair and representative.
Step 3: The Iterative Swap (The “Balancing Act”)
This is where the magic happens. After initialization, NetDAG runs an iterative process to lower the average EMD (improve accuracy) without ruining the bandwidth optimization.
-
Iterative Refinement: The algorithm loops through the groups (defined by
MAX_ITER) and looks for opportunities to swap clients between groups. -
The Transfer Logic: It proposes moving a client from Group A to Group B based on the bandwidth tiers. It then calculates: Does this move lower the overall EMD? If so the swap is proposed, and calculates a EMDnew score.
-
The COEFF Parameter is our control knob. If a swap involves clients with different bandwidth tiers, the algorithm applies a penalty coefficient (
COEFF). If EMDnew score is lower than EMDold $\times \text{COEFF}$ the transfer happens.
- Strict (COEFF near 0.1): The algorithm creates very fast groups but allows for higher data imbalance.
- Relaxed (COEFF near 1.0): The algorithm prioritizes data balance (Accuracy), even if it means moving a slow client to a larger model and causing a slight delay.
Experiment Setup and Results
Standard Federated Learning research often assumes stable internet connections. We took a different approach. We utilized the CORE (Common Open Research Emulator) to create a network topology where bandwidth is a dynamic variable, not a constant.
-
The Environment
- Hardware: We ran our experiments using Docker containers to represent clients. Each client was limited to 8 CPU cores and 6 GB of memory to simulate the resource constraints of edge devices,.
- Network: We defined 14 different “bandwidth tiers,” ranging from 2.5 to 400 Mbps. Crucially, we programmed the network to update every 5 minutes, randomly shifting clients between bandwidths to mimic real-world fluctuations (e.g., a car driving into a tunnel or a phone switching from Wi-Fi to 4G).
-
The Data and Model
- Dataset: We used the CIFAR-10 dataset (60,000 images in 10 classes). While standard, it is complex enough to test the limits of pruned models.
- Model to be pruned and distributed: We started with an AlexNet architecture, modified slightly for CIFAR-10.
- The Challenge (Non-IID): To make the learning difficult, we split the data using a Dirichlet distribution (α=0.3). This created highly “Non-IID” data, meaning some clients might have many “airplane” images but zero “bird” images,.
- Benchmark
To validate our approach, we pitted NetDAG against two industry-standard algorithms: FedAvg (the standard baseline) and FedProx (designed for data heterogeneity).
We tested three specific client grouping strategies to see which could best balance the trade-off between speed and accuracy:
- Basic Grouping (Random): The standard approach, which often creates massive bottlenecks by assigning slow clients to large models.
- Simple Network-Aware: Optimizes purely for speed by giving small models to slow clients, but fails to account for data bias, leading to low accuracy.
Success was measured on three key metrics: Validation Accuracy, Communication Latency (round duration), and Data Fairness (EMD score).
Results
We ran the NAFNAS framework through 15 iterations of pruning with 56 and 210 clients. We compared our NetDAG algorithm against two industry baselines: FedAvg (the standard) and FedProx (designed for heterogeneity).
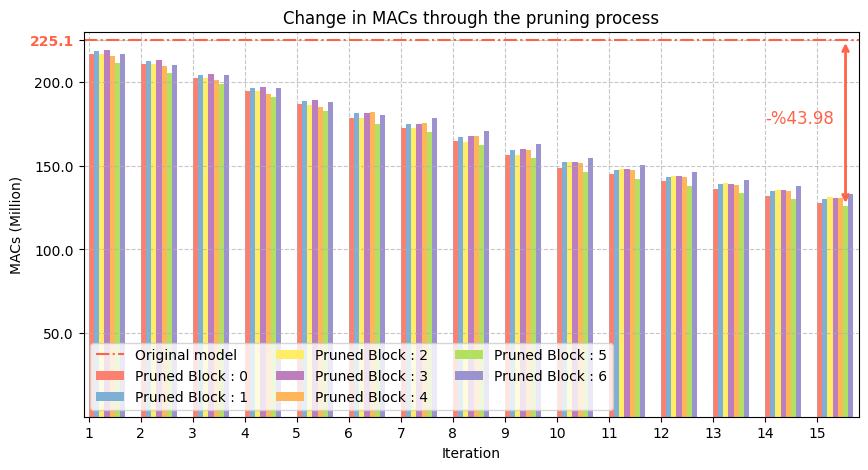
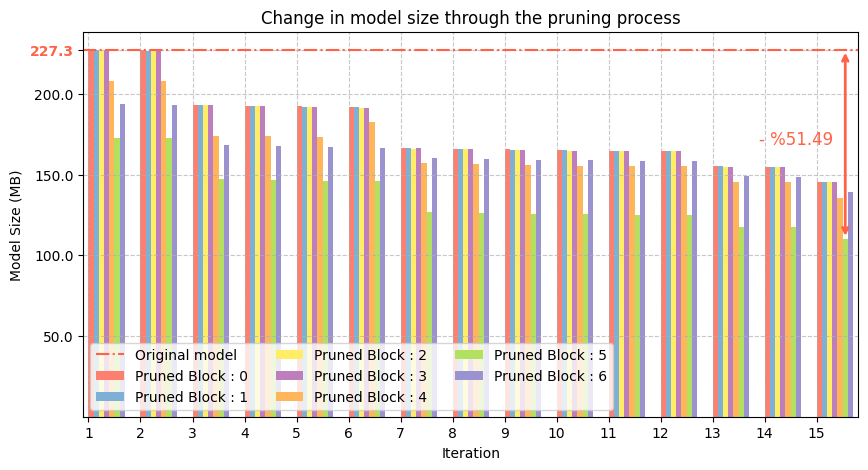
Massive Reductions in Size
The first question was simple: Can we actually make the model smaller? Over 15 iterations, our pruning engine successfully reduced the computational cost (MACs) by 42.98% and the model size (in Megabytes) by 51.49%,.
Accuracy at Scale
The true test came when we pushed the models to their limit. As we pruned the AlexNet model down to 60% and 55% of its original size, standard algorithms began to struggle.
| No. Clients | Algorithm | 85% AlexNet | 70% AlexNet | 60% AlexNet | 55% AlexNet |
|---|---|---|---|---|---|
| 56 | FedAvg | 56.90 | 55.87 | 54.00 | 53.01 |
| 56 | FedProx | 58.42 | 57.81 | 55.55 | 55.65 |
| 56 | Network Aware | 53.05 | 53.74 | 52.70 | 52.39 |
| 56 | NetDAG | 55.77 | 56.21 | 55.70 | 56.46 |
| 210 | FedAvg | 46.39 | 59.86 | 65.65 | 65.92 |
| 210 | FedProx | 31.83 | 38.60 | 39.59 | 38.43 |
| 210 | Network Aware | 43.56 | 56.79 | 65.32 | 65.75 |
| 210 | NetDAG | 43.74 | 61.57 | 66.93 | 67.56 |
%60 Alexnet: Model’s size is reduced to %60 of the initial size.
-
56 Clients: NetDAG achieved 56.46% accuracy on the 55% pruned model, outperforming both FedAvg (53.01%) and the Simple Network-Aware approach (52.39%).
-
210 Clients: The gap widened. NetDAG achieved 67.56% accuracy, significantly beating FedAvg (65.92%) and crushing FedProx (38.43%).
Round Duration
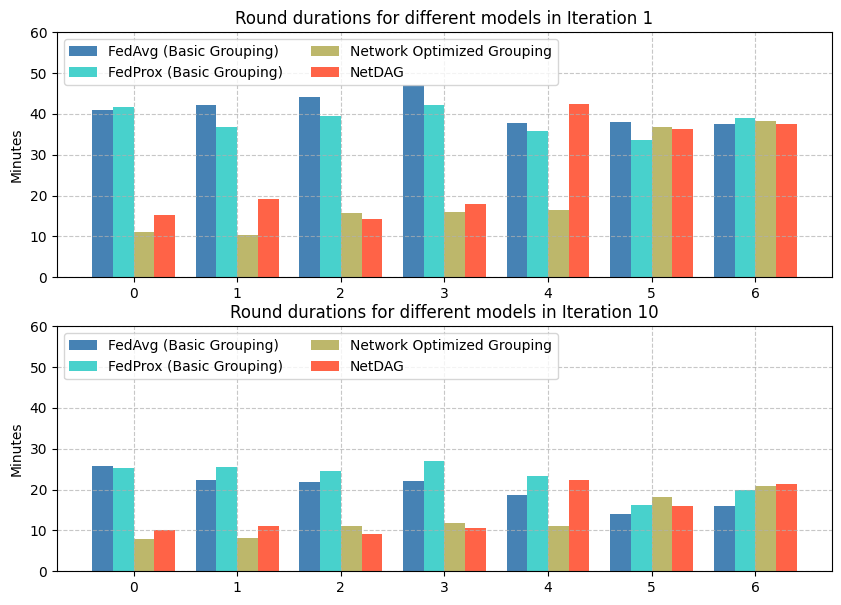
We compared three grouping strategies to see which one balanced speed and accuracy best:
- Basic Grouping (Random): Randomly assigns clients.
- High latency because slow clients were often assigned to large models, creating bottlenecks.
- Simple Network-Aware Grouping: Simply assigns the slowest clients to the smallest models.
- Fast, but inaccurate. By grouping only based on speed, it ignored data distribution, causing accuracy to drop significantly,.
- NetDAG (Our Solution): Balances bandwidth and data distribution (EMD).
- It sacrificed a small amount of speed compared to the “Simple” approach but maintained high accuracy by ensuring fair data representation.
Summary
This research proved that network bottlenecks has an impactful role in FL environments and data heterogenity both effect validation accuracy and NAS performance.
Our open-source framework NAFNAS is a useful for FL and network emulations. Proposed FL client grouping algorithm NetDag successfully optimizes these bottlenecks and improves both communication delay and aggregated model performance.